來源:資料STUDIO 作者:雲朵君一、python-docx讀取Word檔案在做資料分析時,雖然操作docx並不是常用操作,但有些時候,資料分析師拿到的檔案是docx或doc的Word檔案,尤其是對資料具有
2021-07-09 03:05:03
來源:資料STUDIO
作者:雲朵君
一、python-docx讀取Word檔案
在做資料分析時,雖然操作docx並不是常用操作,但有些時候,資料分析師拿到的檔案是docx或doc的Word檔案,尤其是對資料具有至關重要的資料字典。接下來以一個數據字典為例來介紹下python-docx讀取Word檔案的基本操作。並將Word中的表格內容寫入excel中。
1、Word原檔案

2、安裝python-docx
>>> pip install python-docxCollecting python-docxDownloading python-docx-0.8.10.tar.gz (5.5 MB) |████████████████████████████████| 5.5 MB 1.1 MB/sRequirement already satisfied: lxml>=2.3.2 in ...Successfully built python-docxInstalling collected packages: python-docxSuccessfully installed python-docx-0.8.10
3、讀取檔案
from docx import Document# 開啟文件doc = Document('word.docx')# 讀取每段內容pl = [ paragraph.text for paragraph in doc.paragraphs]# 輸出讀取到的內容for i in pl:print(i)
1.資料字典此處是對每個資料模型中的資料流向所涉及的表進行表結構的詳細說明。1.1表格1.1.1 組織機構 ORGANIZATION1.1.2 科室 DEPARTMENT1.1.3 職工 EMPLOYEE
4、讀取標題
from docx import Documentdoc = Document('word.docx')for p in doc.paragraphs:style_name = p.style.name if style_name.startswith('Heading'): print(style_name,p.text,sep=':')
Heading 1:1.資料字典Heading 2:1.1表格
這邊主要用到style屬性,可以通過p.style.name檢視每段內容的style。
for p in doc.paragraphs:
print(p.style.name)
Heading 1List ParagraphHeading 2NormalNormalNormalNormalNormalNormal
5、讀取一級標題
for p in doc.paragraphs:style_name = p.style.name if p.style.name == 'Heading 1': print(p.text)
1.資料字典
6、讀取所有標題
import refor p in doc.paragraphs:if re.match('^Heading d+$', p.style.name): print(p.text)
1.資料字典1.1表格
7、讀取正文
for p in doc.paragraphs:if p.style.name == 'Normal': print(p.text)
8、讀取其他內容
from docx.enum.style import WD_STYLE_TYPEfor s in doc.styles:if .name == WD_STYLE_TYPE.PARAGRAPH: print(s.name)
都有哪些
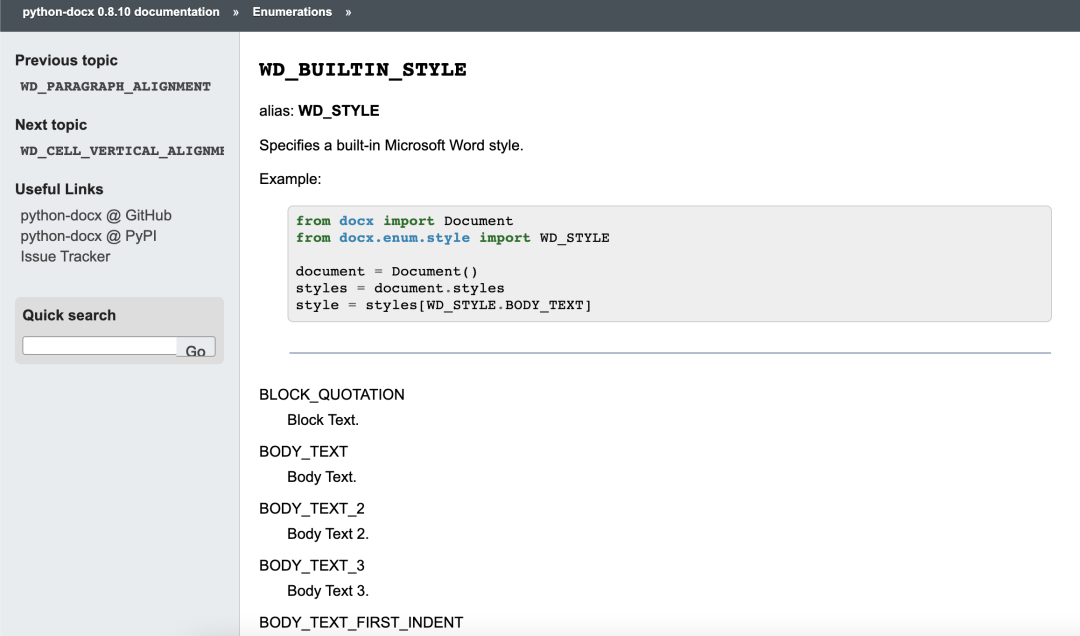
style.name可以在官網檢視
(https://python-docx.readthedocs.io/en/latest/api/enum/WdBuiltinStyle.html):

9、讀取表格
使用tables屬性,可以讀取所有的表格;
from docx import Documentdocument = Document("word.docx")for each in document.tables:print(each)print(document.tables[0].cell(0,0).text)
<docx.table.Table object at 0x7fb75c042450> # 表格物件<docx.table.Table object at 0x7fb75c042210><docx.table.Table object at 0x7fb75c042650>名稱 # 第一個表格中第一個單元格的內容
本例讀取方法如下:
# 讀取表格材料,並輸出結果tables = [table for table in doc.tables]for table in tables:for row in table.rows: for cell in row.cells: print(cell.text,end=' ') print() print('n')
名稱 類型 是否為空 預設 釋義id varchar2(32) 機構IDparent_id varchar2(32) y 上級機構IDcode varchar2(10) y 組織機構程式碼type varchar2(10)name varchar2(60) 機構名稱abbreviation varchar2(60) 縮寫名稱 類型 是否為空 預設 釋義code varchar2(4) 科室IDorganization_id varchar2(32) y 機構IDtype varchar2(16) y 類別/科室屬性name varchar2(60) 科室名稱名稱 類型 是否為空 預設 釋義sstaffno varchar2(32) 職工IDname varchar2(60) 姓名organization_id varchar2(8) 所屬機構IDorganization_name varchar2(64) 所屬機構名稱sex varchar2(6) 性別password varchar2(32) y 密碼
下面擴展兩個常用操作。
10、doc轉docx
由於python-docx只能處理docx格式的Word文件,如果需要對doc格式的文件進行處理,則需要將doc轉docx,再進行處理。
安裝
python -m pip install pypiwin32
完整操作
import os
import time
import win32com
from win32com.client import Dispatch
def doc_to_docx(path):
# 呼叫word程式
w = win32com.client.Dispatch('Word.Application')
# 後臺運行,不顯示,不警告
w.Visible = 0
w.DisplayAlerts = 0
doc = w.Documents.Open(path)
# 這裡必須要絕對地址,保持和doc路徑一致
newpath = allpath+'\轉換後的文件.docx'
time.sleep(3) # 暫停3s,否則會出現-2147352567,錯誤
doc.SaveAs(newpath,12,False,"",True,"",False,False,False,False)
# doc.Close() 開啟則會刪掉原來的doc
w.Quit()# 退出
return newpath
allpath = os.getcwd()
print(allpath)
doc_to_docx(allpath+'\轉換前的文件.doc')
11、轉換word為pdf
import win32com
from win32com.client import Dispatch, constants
import os
# 生成PDF檔案
def funGeneratePDF():
word = Dispatch("Word.Application")
word.Visible = 0 # 後臺運行,不顯示
word.DisplayAlerts = 0 # 不警告
doc = word.Documents.Open(os.getcwd() + "\win32com轉換word為pdf等格式.docx")
# 開啟一個已有的word文件
doc.SaveAs(os.getcwd() + "\win32com轉換word為pdf等格式.pdf", 17)
# txt=4, html=10, docx=16, pdf=17
doc.Close()
word.Quit()
二、openpyxl寫入Excel
使用第三方模組:
openpyxl
pip install openpyxl
1、新建一個新的Excel
先匯入openpyxl模組,並且創建一個工作簿,且創建了一個只包含一個工作表的工作簿。
import openpyxlmywb = openpyxl.Workbook()
確認工作表的名字,數量和活動的工作表。
>>> mywb.get_sheet_names()['Sheet']>>> sheet = mywb.active>>> sheet.title'Sheet'
修改工作表名稱,並儲存。
>>> sheet.title = 'DataDict'>>> wb.get_sheet_names()['DataDict']>>> mywb.save('NewExcelFile.xlsx')
2、載入Excel檔案並儲存
在把一個現有的excel檔案讀入記憶體,並對它進行一系列修改之後,必須使用save()方法,將其儲存,否則所有的更改都會丟失。
import openpyxlmywb = openpyxl.load_workbook('filetest.xlsx')sheet = mywb.activesheet.title = 'Working on Save as'mywb.save('example_filetest.xlsx')
3、創建一個新工作表sheet
>>> import openpyxl>>> mywb = openpyxl.Workbook()>>> mywb.get_sheet_names()['Sheet']>>> mywb.create_sheet()<Worksheet "Sheet1">>>> mywb.get_sheet_names()['Sheet', 'Sheet1']>>> wb.create_sheet(index=0, title='1st Sheet')<Worksheet "1st Sheet">>>> mywb.get_sheet_names()['1st Sheet', 'Sheet', 'Sheet1']>>> mywb.create_sheet(index=2, title='2nd Sheet')<Worksheet "2nd Sheet">>>> mywb.get_sheet_names()['1st Sheet', 'Sheet', '2nd Sheet', 'Sheet1']
使用create_sheet()方法創建的新工作表預設排在工作簿的最後一個,也可以用index具體規定新建工作表的位置,並且可以在創建的同時對其命名。使用index排序的規則繼承了python的排序方法,index從0開始。
4、刪除工作表
>>> mywb.get_sheet_names()['1st Sheet', 'Sheet', '2nd Sheet', 'Sheet1']>>> mywb.remove_sheet(mywb.get_sheet_by_name('1st Sheet'))>>> mywb.remove_sheet(mywb.get_sheet_by_name('Sheet1'))>>> mywb.get_sheet_names()['Sheet', '2nd Sheet']
在最後不要忘記使用save()方法對所作更改進行儲存。
5、向單元格中寫入資料
>>> import openpyxl>>> mywb = openpyxl.Workbook()>>> mysheet = mywb.get_sheet_by_name('Sheet')>>> mysheet['F6'] = 'Writing new Value!'>>> mysheet['F6'].value 'Writing new Value'
6、cell
同樣可以用cell()函數指向單元格,並且對其寫入資料。
>>> import openpyxl>>> mywb = openpyxl.Workbook()>>> mysheet = mywb.get_sheet_by_name('Sheet')>>> mysheet.cell(row=2, column=4).value = 'Let's try again!'>>> mysheet['D2'].value'Let's try again!'
7、append
對於寫入,只需要建立一個list進行append就好了,如果excel為空的那append就從第一行開始遞增操作,你也可以理解為一個ws.append()操作就相當於寫入一行,如果excel為有資料的時候,那寫入操作從沒有資料的那一行開始寫入。
# coding=utf-8from openpyxl import Workbookimport numpy as npwb = Workbook()ws = wb.create_sheet("test")label = [[0],[1], [2], [3]]feature = [[11, 12, 13, 14, 15], [21, 22, 23, 24, 25], [31, 32, 33, 34, 35], [41, 42, 43, 44, 55],]# 多數時候是在numpy格式下計算的,因此此處模擬一下預處理label = np.array(label)feature = np.array(feature)label_input = []for l in range(len(label)): label_input.append(label[l][0])label_input>>> [0, 1, 2, 3]ws.append(label_input)for f in range(len(feature[0])): ws.append(feature[:, f].tolist())wb.save("test.xlsx")
得到結果如下:

因此,我們將上面讀取過程稍作修改,邊讀取邊寫入。
from openpyxl import Workbookfrom docx import Document# 開啟文件doc = Document('word.docx')# 新建一個工作簿wb = Workbook()# 新建一個工作表,並命名為'word'ws= wb.create_sheet("word")# 讀取表格材料,並輸出結果tables = [table for table in doc.tables]for table in tables:for row in table.rows: list_rows = [] for cell in row.cells: list_rows.append(cell.text) # print(list_rows) ws.append(list_rows)wb.save("word2excel.xlsx")
得到:

8、報錯處理
最後介紹一個報錯,避免踩坑。
moduleNotFoundError:No module named 'exceptions'主要還是直接下載docx版本不相容如果pip install docx 過請先解除安裝,輸入如下指令:pip uninstall docx方法一:pip install python-docx方法二: 下載:python_docx-0.8.6-py2.py3-none-any.whl下載地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/命令列輸入pip install python_docx-0.8.6-py2.py3-none-any.whl 重新下載docx包,問題解決。(豆瓣源)pip(3) install python-docx -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
相關文章
來源:資料STUDIO 作者:雲朵君一、python-docx讀取Word檔案在做資料分析時,雖然操作docx並不是常用操作,但有些時候,資料分析師拿到的檔案是docx或doc的Word檔案,尤其是對資料具有
2021-07-09 03:05:03

機器之心專欄作者:常清中國科學院自動化研究所智慧感知與計算研究中心聯合華為等企業提出面向行業的視覺物體檢測一站式解決方案 GAIA。在深度學習與大資料的浪潮下,視覺目標
2021-07-09 03:04:25

博雯 發自 凹非寺量子位 報道 | 公眾號 QbitAI機器會怎樣來看世界?通過幀。傳統的影象感測器會通過每秒捕獲多張靜止影象來記錄場景運動。如果將這一系列影象通過足夠快的速
2021-07-09 03:03:32

膝上型電腦CPU天梯圖,膝上型電腦CPU排行,是按照CPU的跑分進行排序,進行綜合性能對比。可以一定程度上反應CPU的效能優劣,方便進行膝上型電腦CPU對比。 2019年的CPU天梯圖,基本
2021-07-09 03:03:23

第一款 OLED iPad據供應鏈訊息指出,蘋果將會在 2023 年釋出新一代設計的 iPad Air 產品,而在此之前,iPad Air 都只會是小的例行更新。從供貨安排來看,新款 iPad Air 2023 款將會
2021-07-09 03:03:06

摩托羅拉曾經是全球銷量非常好的手機廠商,在安卓前時代,有些機型銷量甚至超過1億部,不過自從被聯想收購後,摩托羅拉沒有以前的輝煌了,如果沒有被聯想收購,摩托羅拉會不會更好,這個
2021-07-09 03:03:00