近日,愛奇藝深度學習雲演算法團隊聯合慕尼黑工業大學的研究者提出了一套高精度手部重建系統,通過「看」單目 RGB 人手圖片即能實現高精度 3D 重建,不僅重新整理了兩個線上測評
2021-08-08 03:03:16
近日,愛奇藝深度學習雲演算法團隊聯合慕尼黑工業大學的研究者提出了一套高精度手部重建系統,通過「看」單目 RGB 人手圖片即能實現高精度 3D 重建,不僅重新整理了兩個線上測評榜單,而且有可能在愛奇藝下一代 VR 裝置中大顯身手。
2016 年,Facebook 正式發售 Oculus Rift 頭戴式 VR 裝置,大大革新了人們對於 VR 技術的認知,這一年也因此被稱為 VR 元年。5 年過去,現在 VR 技術發展到哪了?從原生 VR 遊戲《半條命:愛莉克斯》來看,在這類遊戲場景下,人們與虛擬世界的互動上已經非常成熟。

出自《半條命:愛莉克斯》遊戲。
但是,龐大的頭顯裝置仍是阻礙 VR 應用普及的重要原因。仍以《半條命:愛莉克斯》為例,這部遊戲的精華在於手部互動,而實現撿東西、扔東西、扣動扳機等複雜的虛擬互動,需要一部 VR 頭盔和一部 VR 手柄才能完成。
近日,計算機視覺領域國際頂會 ICCV 2021 收錄了一篇題為《I2UV-HandNet: Image-to-UV Prediction Network for Accurate and High-fidelity 3D Hand Mesh Modeling》的論文。論文由愛奇藝深度學習雲演算法團隊聯合慕尼黑工業大學的研究者完成,他們提出一套名為 I2UV-HandNet 的高精度手部重建系統,通過「看」單目 RGB 人手圖片即能實現高精度 3D 重建。

論文地址:https://arxiv.org/abs/2102.03725
言外之意,如果將這項技術「適配」到帶有攝像功能的眼鏡或者頭盔中,那麼使用者即使不用手柄,也能實現與虛擬世界的高質量對話。
重建效果如何呢?該論文已經在頗受認可的 HO3D 線上測評榜上力壓群雄,持續數月排名第一。在 Freihand 線上測評榜上,截至論文編寫時仍排名第一。

HO3D 榜單排行結果,紅框處為愛奇藝。

論文編寫時 Freihand 榜單排行結果,紅框處為愛奇藝。
目前,研究者們正在嘗試將該技術應用到愛奇藝下一代 VR 裝置中,從而減少對手柄的依賴,打造出更輕、更快和更舒適的 VR 裝置。同時,手勢重建、互動技術目前也同步在愛奇藝其他業務場景和硬體終端進行落地探索,相信不久後會相繼和使用者見面。
I2UV-HandNet:業界首創的手部 3D 重建技術
在人機互動和虛擬現實的應用中,高精度的人手 3D 重建技術發揮著重要作用。但由於手勢多變以及嚴重的遮擋,現有的重建方法在準確性和精度方面仍差些火候。
一方面,目前學術界在進行手部 3D 重建評測,比如在 Freihand 資料集上進行評測主要是突出演算法的精度優勢,不需要考慮算力、延遲等,所以可以採用計算複雜度非常高(如 transformer 等)的一些演算法。
另一方面在工業界,特別是 VR 等移動端裝置,在算力、功耗、電池的續航及發熱等各方面有嚴格限制,在應用上必須採用計算複雜度偏低的演算法。
而 VR 等裝置的攝像頭因為移動端硬體的功耗、續航限制必須降低清晰度而不採用高清晰度的攝像頭,採集到的影象清晰度相對偏低,這對於演算法的識別就構成一定的挑戰性。

I2UV-HandNet 框架圖,由 AffineNet 和 SRNet 組成。
愛奇藝研究者提出的 I2UV-HandNet 獨創性地將 UV 對映表徵引入到 3D 手勢和形狀估計中,他們設計的 UV 重建模組 AffineNet 能夠從單目影象中預測手部網路(hand mesh),從而完成由粗到精的人手 3D 模型重建。
這一設計意味著對於 3D 重建中所需空間中的景深資訊,不用再通過昂貴的硬體完成偵測,在普通 RGB 攝像頭拍攝的圖片中就可以完成景深資訊獲取。
I2UV-HandNet 另一個組成部分是 SRNet 網路,其作用是對已有人手 3D 模型進行更高精度的重建。SRNet 網路以研究團隊獨創的「將點的超分轉化為影象超分的思想」為原則,實現在不增加過多計算量的情況下,進行上萬點雲的超分重建。
此外,由於缺乏高保真的手部資料來訓練 SRNet,研究團隊構建了一個名為 SuperHandScan 的掃描資料集訓練 SRNet。由於 SRNet 的輸入是基於 UV 的「粗糙」手部網格。因此 SRNet 的應用範圍很廣,換句話說,一個「訓練有素」的 SRNet 可以對任何粗手部網格進行超解析度重建。
據介紹,在未做任何優化情況下,SRNet 和 AffineNet 組成的 I2UV-HandNet 系統能夠在 Nvidia v100 上達到 46 fps;而經過工程優化後的版本能夠在驍龍 865 CPU+DSP 下達到實時。
為了驗證 I2UV-HandNet 方法對姿態的魯棒性,研究團隊選用了包含大量姿態的真實人手資料集 FreiHAND 作為測試集,並通過 FreiHAND Competition 線上測評與相關 SOTA 工作進行對比,結果如下表 1 所示,證明了該 UV 重建方法的有效性。

在 FreiHAND 上進行真實場景下多姿態的人手 3D 重建對比,↓表示越低越好,↑表示越高越好。
同時為了驗證在各種遮擋場景下的重建效能,研究團隊選取包含大量遮擋樣本的 HO3D 資料集進行測評,結果如下表 2 所示,各項指標也都達到了 SOTA。

在 HO3D 上進行真實場景下具有遮擋的人手 3D 重建實驗對比,↓表示越低越好,↑表示越高越好。
為了定量評價 SRNet,研究團隊還在 HIC 資料集上進行了實驗。如下表 3 所示,SRNet 的輸出 (表中的「OUTPUT」) 得到了優於原始深度圖的結果。

↓表示越低越好,↑表示越高越好。
模型詳解:AffineNet+SRNet=I2UV-HandNet
如下為 AffineNet 網路框架圖,AffineNet 由編碼網路和解碼網路組成,在解碼時通過 Affine Conection 和多 stage 完成由粗到精的 UV 學習。

更具體地,AffineNet 由編解碼網路組成,編碼骨幹網路為 ResNet-50,解碼時採用由粗到精的層級結構,其中 Affine Connection 是指通過當前層級預測的 UV 用仿射變換(類似 STN)的方式實現編碼特徵向 UV 圖的對齊,即:

同時有:

以及:

其中 E^i 表示 1/2^i 解析度下的編碼特徵圖,f_up (x)表示將 x 放大 2 倍,π(I_UV)表示根據稠密的 I_UV 在固定投影矩陣的投影座標,f_ac (x,y)表示 Affine Connection 操作,即使用 x 對 y 進行仿射變換,A ^i 表示通過仿射變換後與 UV 對齊後的特徵圖,相對於 E^i,其包含更多與手相關的特徵。D^i 表示 1/2^i 解析度下的解碼特徵圖,f_con (x,y,z)表示通過 x,y,z 生成 UV 圖。
通過上面兩個公式看出,解碼過程本質上就是一套低解析度 UVmap 到高解析度 UVmap 重建的過程,同時也是 3D 點雲重建由粗到精的過程。
AffineNet 的損失函數分為 3 項:

其中,使用 L1 作為 UV 的重建 Loss:

I_UV^* 為真實 UV 圖,I_UV 為重建結果,M(i,j)=0 表示 UV 圖上沒有被 3D 點雲對映,對應 UV 的 RGB 值為(0,0,0)。
UV 圖本質上可以看成將 3D 模型上每個三角面不重疊地對映到二維平面,所以在 UV 圖上對應的三角片區域的值應該是連續的,因此引入 Grad loss:

其中_u 和_v 分別表示在 UV 圖的 u 和 v 方向求梯度。
在訓練階段對解析度最大的 4 個 stage(即 i=0,1,2,3)重建的 UV 進行 L_affine 優化,其中λ_1=λ_2=λ_3=1,投影矩陣選用正投影矩陣,每個 stage 間的 loss 比例都為 1。

SRNet 每層的設定。
SRNet 的網路結構類似於超解析度卷積神經網路(SRCNN),但輸入和輸出是 UV 圖而非 RGB 影象。
研究團隊巧妙地通過 UV 圖的方式將點的超分轉換為影象的超分,將偽高精度 UV 圖作為輸入,高精度 UV 圖作為標籤,通過偽高精度 3D 模型生成的 UV 圖到高精度 3D 模型生成的 UV 圖的超分學習,完成 1538 個面到 6152 個面,778 個點到 3093 個點的超分學習,超分 Loss 設計如下:

在測試階段只需要將 AffineNet 重建的 UV 圖作為輸入,便可得到經過超分重建後的高精度 UV 圖,從而實現人手的高精度 3D 重建。
將 AffineNet 和 SRNet 結合成 I2UV-HandNet 系統便可完成 High-fidelity 的人手 3D 重建。為了快速驗證將點的超分轉化為影象的超分的可行性,研究團隊將 SRCNN 網路結構用於 SRNet 中,並選取 QSH 資料集進行訓練。
Batch size 設定為 512,輸入 UV 圖的大小為 256*256,初始學習率為 1e-3,優化器 Adam,並採用 cosine lr 下降方式,並在 scale、旋轉等方面進行資料增廣。
同時為了網路模型具有更好的泛化性,也隨機對高精度 UV 圖進行高斯平緩處理,並將結果作為網路的輸入。在測試時,研究團隊將 AffineNet 輸出的 UV 圖作為 SRNet 的輸入實現 I2UV-HandNet 系統的 high-fidelity 3D 人手重建。
下圖展示了 I2UV-HandNet 在各種姿態和遮擋條件下基於單目 RGB 圖的人手 High-fidelity 3D 重建結果。從圖中 Coarse Mesh 和 High-fidelity meshes 的對比可以看出,通過 UV 圖超分輸出的包含 3093 個點 / 6152 個面的 3D 模型(High-fidelity)明顯要比 AffineNet 輸出的包含 778 個點 / 1538 個面的 MANO 模型(Coarse Mesh)更加精細,具體表現在摺痕細節和面板鼓脹等。

在 HO-3D 資料集(左)和 FreiHAND 資料集(右)上的重建結果。從左到右依次為:輸入、AffineNet 的重建結果、SRNet 輸出的超分結果(high-fidelity)
研究團隊還對 UV 的展開方式和由粗到精的形式進行了屬性消融實驗分析,實驗在 FreiHAND 測試集上進行。如下圖所示,通過 MAYA 對 MANO 模型從左到右分別按照黑線的位置對其進行 UV 展開,並依次記為 UV_1、UV_2 和 UV_3。

相同人手模型(上)的不同 UV(下)展開形式,剖開方式按照黑線位置,展開後的 UV 圖每個區域通過顏色與手部相對應。
對不同 UV 形式進行實驗分析,分析結果如下表 6 所示,不同 UV 展開結果對演算法有一定的影響。其中 UV_1 按照物體等面積佔比展開,UV_2 和 UV_3 按照人手各區域點數佔比展開,故 UV_1 效果最差。
UV_3 與 UV_2 區別在於手指排布不同,研究團隊認為人手的 5 個手指尖間的特徵具有一定的聯絡,同時從影象卷積方式出發,將點數最多的 5 根手指放在一起更有利於 UV 的重建學習,UV_3 優於 UV_2。
同時,研究團隊在 UV_3 的基礎上對 AffineNet 由粗到精的學習進行分析,對進行 Loss 優化的每個 stage 輸出的 UV 圖進行測評,測評結果如下表 7 所示,隨著 UV 解析度的增加,姿勢和網格的 AUC 值呈上升趨勢,說明 3D 重建結果也越加好,但在全解析度時有所下降。
分析資料認為,通過優化得到的 GT 網格並不能和原圖在畫素級別實現很好的重疊,所以學習畫素級別精度網格意義不大。

UV 形式和由粗到精的實驗分析,其中 UVi 表示不同的 UV 形式,Si 示表示用對應 stage 的輸出結果(1/2i 全解析度 UV)進行測評。
下一步:「適配」更加豐富的應用場景
手部重建與人體重建比較相似,當前學術界做人體重建的演算法可以遷移到手部的應用。但相對於比較火熱的人臉重建,手部和人體存在自遮擋更多、姿態複雜度更高等問題,因此研究難度大,業界可借鑑的資料、行業內的應用都相對較少。
但手部、人體重建卻是用自然的肢體語言實現人機互動的關鍵技術,相比一些可穿戴裝置,更能帶來體驗和沉浸度。例如手柄無法模擬手指每一個關節的活動,手部重建則能實現更加精細的操控。這意味著能夠擴展至遊戲、數字化工廠、虛擬場景培訓等更多場景。
接下來,愛奇藝技術團隊將會致力於演算法的計算效率提升,能夠更好地滿足 VR 裝置應用場景對功耗及計算資源的嚴苛要求;同時也會繼續研究當前學術界的一些難題,例如對於重疊 / 遮擋的手的重建,愛奇藝深度學習雲演算法團隊也已經開始佈局。
相關文章

近日,愛奇藝深度學習雲演算法團隊聯合慕尼黑工業大學的研究者提出了一套高精度手部重建系統,通過「看」單目 RGB 人手圖片即能實現高精度 3D 重建,不僅重新整理了兩個線上測評
2021-08-08 03:03:16

魚羊 發自 凹非寺量子位 報道 | 公眾號 QbitAI馬斯克的史上最高火箭,現在已經組裝上了。具體有多高?先來張照片感受一下:△圖源:馬斯克twitter這一新建造的星艦系統總體高度達12
2021-08-08 03:03:06
出品|開源中國文|御阪弟弟Visual Studio Code 1.59 現已釋出,其中一些主要亮點內容如下:工作臺擴展改進了關於調整大小的擴展檢視。預設寬度的擴展檢視顯示了所有詳細資訊(以前
2021-08-08 03:02:41
8月5日,位元組跳動旗下大力裁員教育板塊員工。內部員工表示教育將採取N+2的賠償,而且各種攢的年假都可以享受兩倍天數回家休息。裁員的不止有位元組,同時還有高徒,涉及上萬人的
2021-08-08 03:02:36
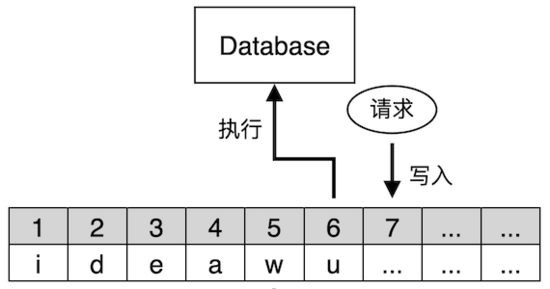
在電腦科學領域,狀態機複製或狀態機方法是實現容錯服務的一種常規方法,主要通過複製伺服器,並協調客戶端和這些伺服器映象間的互動來達到目標。這個方法也同時提供了理解和設計
2021-08-08 03:02:32

暫時別買 iPhone12相信大家經常能看到關於今年 iPhone13 的各種爆料訊息,按照以往的爆料經驗來看,今年 iPhone13 的這些訊息準確度至少有 90% 左右。所以現在每當身邊有朋友問
2021-08-08 03:02:26