GPT-3 強大,但不是很「聰明」,微軟提出了一種大規模稀疏模型,改進了生產型 Transformer 模型,在自家搜尋引擎Bing上改進並測試,效能大幅提升。
近來 GPT-3 等基於 Transformer 的深度學習模型在機器學習領域受到了很多關注。這些模型擅長理解語義關係,為大幅改進微軟 Bing 搜尋引擎的體驗做出了貢獻,並在 SuperGLUE 學術基準上超越了人類的表現。但是,這些模型可能無法捕獲超出純語義的查詢和文件術語之間更細微的關係。
來自微軟的研究者提出了一種大規模稀疏模型「Make Every feature Binary(MEB)」,它改進了微軟的生產型 Transformer 模型,以提升微軟客戶使用大規模 AI 時的搜尋相關性。為了使搜尋更加準確和動態,MEB 更好地利用了大資料的力量,並允許輸入特徵空間具有超過 2000 億個二值化特徵,這些特徵反映了搜尋查詢和文件之間的微妙關係。
MEB 能夠為基於 Transformer 的深度學習模型提升搜尋相關性,其中一個重要的原因是它可以將單個事實對映為特徵,從而使 MEB 能夠更細緻地理解單個事實。例如,許多深度神經網路 (DNN) 語言模型在填寫一句話的空白時可能會過度泛化:「(blank) can fly」。由於大多數 DNN 訓練樣本的結果是「birds can fly」,因此 DNN 語言模型可能會用「birds」這個詞來填補空白。
MEB 通過將每個事實分配給一個特徵來避免這種情況,例如藉助分配權重來區分飛行能力,它可以針對使鳥等任何實體的每個特徵執行此操作。MEB 與 Transformer 模型搭配使用,可以將模型提升到另一個分類級別,例如模型產生的結果將不是「鳥類會飛」,而是「鳥類會飛,但鴕鳥、企鵝等鳥類除外」。
隨著規模的增加,還有一個元素可以更有效地改進使用資料的方法。Bing 搜尋後的網頁結果排序是一個機器學習問題,它受益於對大量使用者資料的學習。使用者點選資料的傳統利用方法是為每個印象深刻的查詢 / 文件對提取數千個手工構建的數值特徵,並訓練梯度提升決策樹 (GBDT) 模型。
然而,由於特徵表示和模型容量有限,即使是 SOTA GBDT 訓練器 LightGBM 也要在數億行資料後才能收斂。此外,這些手工構建的數值特徵本質上往往非常粗糙。例如,他們可以捕獲查詢中給定位置的術語在文件中出現的次數,但有關特定術語是什麼的資訊在這種表徵中丟失了。此外,該方法中的特徵並不總是能準確地說明搜尋查詢中的詞序等內容。
為了釋放海量資料的力量,並啟用能夠更好反映查詢與文件之間關係的特徵表徵,MEB 在 Bing 搜尋三年中超過 5000 億個查詢 / 文件對上進行訓練。輸入特徵空間有超過 2000 億個二值化特徵。使用 FTRL 的最新版本是具有 90 億個特徵和超過 1350 億個參數的稀疏神經網路模型。
MEB 正用於生產中所有區域和語言的 100% 的 Bing 搜尋。它是微軟提供的最大通用模型,具備一種出色的能力——能夠記住這些二值化特徵所代表的事實,同時以連續的方式從大量資料中進行可靠的學習。
微軟的研究者通過實驗發現,對大量資料進行訓練是大型稀疏神經網路的獨特能力。將相同的 Bing 日誌輸入 LightGBM 模型並使用傳統數值特徵(例如 BM25 等查詢與文件匹配特徵)進行訓練時,使用一個月的資料後模型質量不再提高。這表明模型容量不足以從大量資料中受益。相比之下,MEB 是在三年的資料上訓練的,研究者發現它在新增更多資料的情況下能夠繼續學習,這表明模型容量能夠隨著新資料的增加而增加。
與基於 Transformer 的深度學習模型相比,MEB 模型還展示了超越語義關係的學習能力。在檢視 MEB 學習的主要特徵時,研究者發現它可以學習查詢和文件之間的隱藏關係。
例如,MEB 瞭解到「Hotmail」與「Microsoft Outlook」密切相關,即使它們在語義上並不接近。但 MEB 發現了這些詞之間微妙的關係:Hotmail 是一種免費的基於 Web 的電子郵件服務,由 Microsoft 提供,後來更名為 Microsoft Outlook。同樣,它瞭解到「Fox31」和「KDVR」之間有很強的聯絡,其中 KDVR 是位於科羅拉多州丹佛市的電視訊道的呼號,該頻道以 Fox31 品牌運營,而表面上看這兩個詞之間並沒有明顯的語義聯絡。
更有趣的是,MEB 可以識別單詞或短語之間的負面關係,揭示使用者不希望在查詢中看到的內容。例如,搜尋「棒球」的使用者通常不會點選談論「曲棍球」的頁面,即使它們都是流行運動。瞭解這些負面關係有助於忽略不相關的搜尋結果。
MEB 學習的這些關係與基於 Transformer 的 DNN 模型學習的關係非常互補,搜尋相關性和使用者體驗得到了很好的提升。微軟在生產型 Transformer 模型的基礎上引入 MEB 帶來了以下結果:
頁面中最頂端搜尋結果的點選率 (CTR) 增加了近 2%。這些結果在頁面摺疊上方,無需向下滾動即可找到所需結果。
手動查詢重構減少了 1% 以上。使用者需要手動重新制定查詢意味著他們不喜歡他們在原始查詢中搜索到的結果,因此該比重減少說明了模型效能的提升。
「下一頁」等分頁點選量減少了 1.5% 以上。使用者需要點選「下一頁」按鈕意味著他們沒有在第一頁找到他們想要的東西。
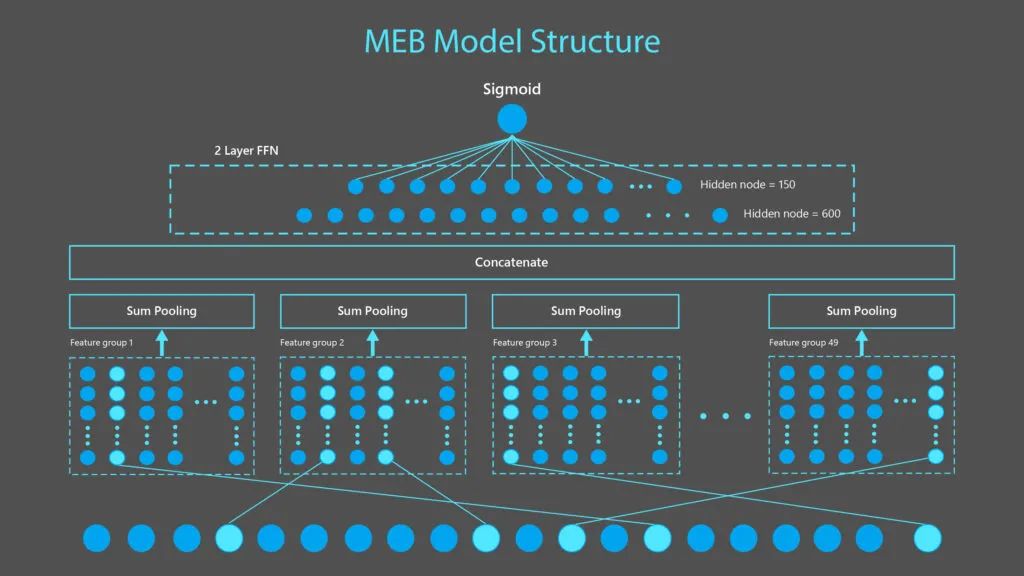
如下圖 1 所示,MEB 模型是由 1 個二值化特徵輸入層、1 個特徵嵌入層、1 個池化層和 2 個密集層組成。輸入層包含從 49 個特徵組生成的 90 億個特徵,每個二值化特徵被編碼為一個 15 維嵌入向量。在每組 sum-pooling 和拼接(concatenation)之後,向量通過 2 個密集層來產生點選概率估計。
圖 1:MEB 是一個稀疏神經網路模型,由一個接受二值化特徵的輸入層、一個將每個二值化特徵轉換為 15 維向量的特徵嵌入層、一個應用於 49 個特徵組中每個特徵組並拼接以產生一個 735 維向量的 sum pooling 層,然後通過兩個密集層來產生一個點選概率。如下圖 2 所示,上圖 1 中顯示的功能是從樣例查詢「Microsoft Windows」和連結:https://www.microsoft.com/en-us/windows 中的文件中生成的。
MEB 使用來自 Bing 的三年搜尋日誌作為訓練資料。對於每次 Bing 搜尋的結果,該研究使用啟發式方法來確定使用者是否對他們點選的文件感到滿意。研究者將「令人滿意」的文件標記為正樣本。同一搜尋結果中的其他文件被標記為負樣本。對於每個查詢和文件對,從查詢文字、文件 URL、標題和正文文字中提取二值化特徵。這些特徵被輸入到一個稀疏神經網路模型中,以最小化模型預測的點選概率和實際點選標籤之間的交叉熵損失。
特徵設計和大規模訓練是 MEB 成功的關鍵。MEB 特徵是在查詢和文件之間非常具體的術語級別(term–level)或 N-gram–level(N-grams 是含有 N 個術語的序列)關係上定義的,傳統的數值特徵無法捕獲這些特徵,傳統的數值特徵只關心查詢和文件之間的匹配計數。
為了充分釋放這個大規模訓練平臺的力量,所有的特徵都被設計為二值化特徵,可以很容易地以一致的方式覆蓋手工構建的數值特徵和直接從原始文字中提取的特徵。這樣做可以讓 MEB 在一條路徑上進行端到端的優化。當前的生產模型使用三種主要類型的特徵,包括:
N-gram 對特徵是基於 Bing 搜尋日誌中查詢和文件域的 N-gram 組合生成的。如下圖 2 所示,來自查詢文字的 N-gram 將與來自文件 URL、標題和正文文字的 N-gram 結合形成 N-gram 對特徵。更長的 N-gram(N 值更大)能夠捕捉更豐富和更細微的概念。然而,隨著 N 的增加,處理它們的成本呈指數級增長。在該研究的生產模型中,N 設定為 1 和 2(分別為 unigrams 和 bigrams)。
數值特徵首先通過分桶操作,然後應用 one-hot 編碼將其二值化。在圖 2 所示的示例中,數值特徵「QueryLength」可以採用 1 到 MaxQueryLength 之間的任何整數值。研究者為此特徵定義了 MaxQueryLength 儲存桶,以便查詢「Microsoft Windows」查詢具有等於 1 的二值化特徵 QueryLength_2。
分類特徵可以通過 one-hot 編碼以一種直接的方式轉換為二值化特徵。例如,UrlString 是一個分類特徵,每個唯一的 URL 字元串文字都可以作為一個不同的類別。
圖 2:MEB 特徵示例。左側展示了一個查詢文件對,其中查詢文字、文件標題、URL 和片段作為特徵提取的輸入。右側展示了 MEB 產生的一些典型特徵。
用持續訓練支撐萬億查詢 / 文件對(每日重新整理)
為了實現具有如此巨大特徵空間的訓練,該研究利用由 Microsoft Advertising 團隊構建的內部大型訓練平臺 Woodblock,它是一種用於訓練大型稀疏模型的分散式、大規模、高效能的解決方案。Woodblock 建立在 TensorFlow 之上,填補了通用深度學習框架與數十億稀疏特徵的行業需求之間的空白。通過對 I/O 和資料處理的深度優化,Woodblock 可以使用 CPU 和 GPU 叢集在數小時內訓練數千億個特徵。
但即使使用 Woodblock pipeline,用包含近一萬億個查詢 / 文件對的三年 Bing 搜尋日誌訓練 MEB 也很難一次性完成。因此該研究使用了一種持續訓練的方法,先前已在已有資料上訓練的模型,會在每個月的新資料上進行持續訓練。
更重要的是,即使在 Bing 中實現以後,模型也會通過使用最新的每日點選資料持續訓練而每天重新整理,如圖 3 所示。為了避免過時特徵的負面影響,自動過期策略會檢查每個特徵的時間戳,並刪除過去 500 天內未出現的特徵。經過不斷的訓練,更新模型的日常部署完全自動化。
圖 3:MEB 每天的重新整理流程。生產型 MEB 模型每天都使用最新的單日 Bing 搜尋日誌資料進行持續訓練。在部署新模型並在線提供服務之前,會從模型中刪除過去 500 天內未出現的陳舊特徵。這可以保持特徵的新鮮度並確保有效利用模型容量。
使用 Bing ObjectStore 平臺為超大模型提供服務
MEB 稀疏神經網路模型的記憶體佔用約為 720 GB。在流量高峰期,系統需要維持每秒 3500 萬次特徵查詢,因此無法在一臺機器上為 MEB 提供服務。研究者利用 Bing 的 ObjectStore 服務來支撐 MEB 模型。
ObjectStore 是一種多租戶(multi-tenant)的分散式鍵值儲存系統,能夠儲存資料和計算託管。MEB 的特徵嵌入層在 ObjectStore 中實現為表的查詢操作,每個二值化特徵雜湊被用作鍵,來檢索訓練時產生的嵌入。池化層和密集層部分的計算量更大,並且在承載使用者定義函數的 ObjectStore Coproc(一個 near-data 計算單元)中執行。MEB 將計算和資料服務分離到不同的分片中。每個計算分片佔用一部分用於神經網路處理的生產流量,每個資料分片託管一部分模型資料,如下圖 4 所示。
圖 4:計算分片中的 ObjectStore Coproc 與資料分片之間進行會進行互動,以檢索特徵嵌入並運行神經網路。資料分片儲存特徵嵌入表並支援來自每個 Coproc 呼叫的查詢請求。
由於在 ObjectStore 上運行的大多數工作負載都專門進行儲存查詢,因此將 MEB 計算分片和記憶體中資料分片放在一起可以最大限度地利用多租戶叢集中 ObjectStore 的計算和記憶體資源。分片分佈在多臺機器上的設計還能夠精細控制每臺機器上的負載,以便讓 MEB 的服務延遲降低到幾毫秒內。
研究者發現像 MEB 這樣非常大的稀疏神經網路可以學習與基於 Transformer 的神經網路互補的細微關係。這種對搜尋語言理解的改進為整個搜尋生態系統帶來了顯著的好處:
由於改進了搜尋相關性,Bing 使用者能夠更快地找到內容和完成搜尋任務,減少重新手動制定查詢或點選下一頁的操作;
因為 MEB 能夠更好地理解內容,釋出商和網站管理員可以獲得更多訪問其資源的流量,並且他們可以專注於滿足客戶,而不是花時間尋找有助於排名更高的關鍵字。一個具體的例子是產品品牌重塑,MEB 模型可能能夠自動學習新舊名稱之間的關係,就像「Hotmail」和「Microsoft Outlook」那樣。
如果使用者要使用 DNN 為業務提供動力,微軟的研究者建議嘗試使用大型稀疏神經網路來補充這些模型。特別地,如果擁有大量使用者互動歷史流並且可以輕鬆構建簡單的二值化特徵,則尤其應該使用這種方法。同時他們還建議使用者確保模型儘可能接近實時地更新。