作者 | Andreas Lundblad 譯者 | 彎月 責編 | 歐陽姝黎2010年的某一天,我忙中偷閒去Stack Overflow上賺聲望值。於是,我看到了下面這個問題:怎樣將位元組數輸出成人
2021-06-22 21:01:29

2010年的某一天,我忙中偷閒去Stack Overflow上賺聲望值。
於是,我看到了下面這個問題:怎樣將位元組數輸出成人類可讀的格式?也就是說,怎樣將123,456,789位元組輸出成123.5MB?

隱含的條件是,結果字元串應當在1~999.9的範圍內,後面跟一個適當的表示單位的字尾。
這個問題已經有一個答案了,程式碼是用迴圈寫的。基本思路很簡單:嘗試所有尺度,從最大的EB(10^18位元組)開始直到最小的B(1位元組),然後選擇小於位元組數的第一個尺度。用虛擬碼來表示的話大致如下:
suffixes = [ "EB", "PB", "TB", "GB", "MB", "kB", "B" ]magnitudes = [ 1018, 1015, 1012, 109, 106, 103, 100 ]i = 0while (i < magnitudes.length && magnitudes[i] > byteCount)i++printf("%.1f %s", byteCount / magnitudes[i], suffixes[i])
通常,如果一個問題已經有了正確答案,並且有人贊過,別的回答就很難趕超了。不過這個答案有一些問題,所以我依然有機會超過它。至少,迴圈還有很大的清理空間。

然後我就想到,kB、MB、GB……等字尾只不過是1000的冪(或者在IEC標準下是1024的冪),也就是說不需要使用迴圈,完全可以使用對數來計算正確的字尾。
根據這個想法,我寫出了下面的答案:
public static String humanReadableByteCount(long bytes, boolean si) {int unit = si ? 1000 : 1024;if (bytes < unit) return bytes + " B";int exp = (int) (Math.log(bytes) / Math.log(unit));String pre = (si ? "kMGTPE" : "KMGTPE").charAt(exp-1) + (si ? "" : "i");return String.format("%.1f %sB", bytes / Math.pow(unit, exp), pre);}
當然,這段程式碼並不是太好理解,而且log和pow的組合的效率也不高。但我沒有使用迴圈,而且沒有任何分支,看起來很乾淨。
這段程式碼的數學原理很簡單。位元組數表示為byteCount = 1000^s,其中s表示尺度。(對於二進位制記法則使用1024為底。)求解s可得s = log_1000(byteCount)。
API並沒有提供log_1000,但我們可以用自然對數表示為s = log(byteCount) / log(1000)。然後對s向下取整(強制轉換為int),這樣對於大於1MB但不足1GB的都可以用MB來表示。
此時如果s=1,尺度就是kB,如果s=2,尺度就是MB,以此類推。然後將byteCount除以1000^s,並找出正確的字尾。
接下來,我就等著社群的反饋了。我並不知道這段程式碼後來成了被複制貼上最多的程式碼。

到了2018年,一位名叫Sebastian Baltes的博士生在《Empirical Software Engineering》雜誌上發表了一篇論文,題為《Usage and Attribution of Stack Overflow Code Snippets in GitHub Projects》。該論文的主旨可以概括成一點:人們是否在遵守Stack Overflow的CC BY-SA 3.0授權?也就是說,當人們從Stack Overflow上覆制貼上時,會怎麼註明來源?
作為分析的一部分,他們從Stack Overflow的資料轉出中提取了程式碼片段,並與公開的GitHub程式碼庫中的程式碼進行匹配。論文摘要如是說:
We present results of a large-scale empirical study analyzing the usage and attribution of non-trivial Java code snippets from SO answers in public GitHub (GH) projects.
(本文對於在公開的GitHub項目中使用來自Stack Overflow上有價值的程式碼片段的情況以及來源註明情況進行了大規模的經驗分析,並給出了結果。)
(劇透:絕大多數人並不會註明來源。)
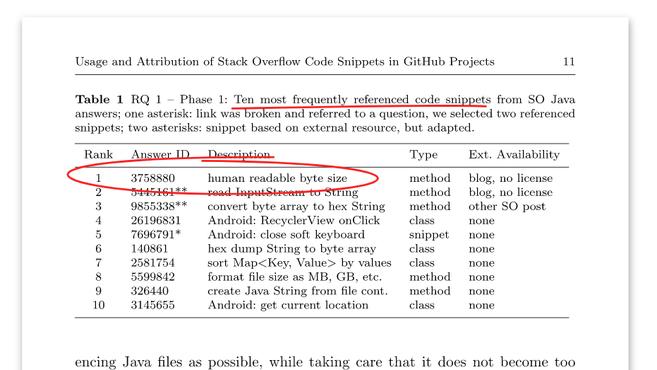
論文中有這樣一張表格:

id為3758880的答案正是我八年前貼出的答案。此時該答案已經被閱讀了幾十萬次,擁有上千個贊。
在GitHub上隨便搜尋一下就能找到數千個humanReadableByteCount函數:

你可以用下面的命令看看自己有沒有無意中用到:
git grep humanReadableByteCount

你肯定在想:這段程式碼有什麼問題:
再來看一次:
public static String humanReadableByteCount(long bytes, boolean si) {int unit = si ? 1000 : 1024;if (bytes < unit) return bytes + " B";int exp = (int) (Math.log(bytes) / Math.log(unit));String pre = (si ? "kMGTPE" : "KMGTPE").charAt(exp-1) + (si ? "" : "i");return String.format("%.1f %sB", bytes / Math.pow(unit, exp), pre);}
在EB(10^18)之後是ZB(10^21)。是不是因為kMGTPE字元串的越界問題?並不是。long的最大值為2^63-1,大約是9.2x10^18,所以long絕對不會超過EB。
是不是SI和二進位制的混合問題?不是。前一個版本的確有這個問題,不過很快就修復了。
是不是因為exp為0會導致charAt(exp-1)出錯?也不是。第一個if語句已經處理了該情況。exp值至少為1。
是不是一些奇怪的舍入問題?對了……

這段程式碼在1MB之前都非常正確。但當輸入為999,999時,它(在SI模式下)會給出「1000.0 kB」。儘管999,999與1,000x1000^1的距離比與999.9x1000^1的距離更小,但根據問題的定義,有效數字部分的1,000是不正確的。正確結果應為"1.0 MB"。
據我所知,原帖下的所有22個答案(包括一個使用Apache Commons和Android庫的答案)都有這個問題(或至少是類似的問題)。
那麼怎樣修復呢?首先,我們注意到指數(exp)應該在位元組數接近1x1,000^2(1MB)時,將返回結果從k改成M,而不是在位元組數接近999.9x1000^1(999.9k)時。這個點上的位元組數為999,950。類似地,在超過999,950,000時應該從M改成G,以此類推。
為了實現這一點,我們應該計算該閾值,並當bytes大於閾值時增加exp的結果。(對於二進位制的情況,由於閾值不再是整數,因此需要使用ceil進行向上取整)。
if (bytes >= Math.ceil(Math.pow(unit, exp) * (unit - 0.05)))exp++;

但是,當輸入為999,949,999,999,999,999時,結果為1000.0 PB,而正確的結果為999.9 PB。從數學上來看這段程式碼是正確的,那麼問題除在何處?
此時我們已經達到了double類型的精度上限。
根據IEEE 754的浮點數表示方法,接近0的數字非常稠密,而很大的數字非常稀疏。實際上,超過一半的值位於-1和1之間,而且像Long.MAX_VALUE如此大的數字對於雙精度來說沒有任何意義。用程式碼來表示就是
double a = Double.MAX_VALUE;double b = a - Long.MAX_VALUE;System.err.println(a == b); // prints true
有兩個計算是有問題的:
String.format參數中的觸發
對exp的結果加一時的閾值
當然,改成BigDecimal就行了,但這有什麼意思呢?而且改成BigDecimal程式碼也會變得更亂,因為標準API沒有BigDecimal的對數函數。
對於第一個問題,我們可以將bytes值縮小到精度更好的範圍,並相應地調整exp。由於最終結果總要取整的,所以丟棄最低位有效數字也無所謂。
if (exp > 4) {bytes /= unit;exp--;}
對於第二個問題,我們需要關心最低有效位元(999,949,99...9和999,950,00...0等不同冪次的值),所以需要使用不同的方法解決。
首先注意到,閾值有12種不同的情況(每個模式下有六種),只有其中一種有問題。有問題的結果的十六進位制表示的末尾為D00。如果出現這種情況,只需要調整至正確的值即可。
long th = (long) Math.ceil(Math.pow(unit, exp) * (unit - 0.05));if (exp < 6 && bytes >= th - ((th & 0xFFF) == 0xD00 ? 51 : 0))exp++;
由於需要依賴於浮點數結果中的特定位元模式,所以需要使用strictfp來保證它在任何硬體上都能運行正確。

儘管還不清楚什麼情況下會用到負的位元組數,但由於Java並沒有無符號的long,所以最好處理複數。現在,-10,000會產生-10000 B。
引入absBytes變數:
long absBytes = bytes == Long.MIN_VALUE ? Long.MAX_VALUE : Math.abs(bytes);
表示式如此複雜,是因為-Long.MIN_VLAUE == LONG.MIN_VALUE。以後有關exp的計算你都要使用absBytes來代替bytes。

下面是最終版本的程式碼:
// From: https://programming.guide/worlds-most-copied-so-snippet.htmlpublic static strictfp String humanReadableByteCount(long bytes, boolean si) {int unit = si ? 1000 : 1024;long absBytes = bytes == Long.MIN_VALUE ? Long.MAX_VALUE : Math.abs(bytes);if (absBytes < unit) return bytes + " B";int exp = (int) (Math.log(absBytes) / Math.log(unit));long th = (long) Math.ceil(Math.pow(unit, exp) * (unit - 0.05));if (exp < 6 && absBytes >= th - ((th & 0xFFF) == 0xD00 ? 51 : 0)) exp++;String pre = (si ? "kMGTPE" : "KMGTPE").charAt(exp - 1) + (si ? "" : "i");if (exp > 4) {bytes /= unit;exp -= 1;}return String.format("%.1f %sB", bytes / Math.pow(unit, exp), pre);}
這個答案最初只是為了避免迴圈和過多的分支的。諷刺的是,考慮到各種邊界情況後,這段程式碼比原答案還難懂了。我肯定不會在產品中使用這段程式碼。

Stack Overflow上的程式碼就算有幾千個贊也可能有問題。
要測試所有邊界情況,特別是對於從Stack Overflow上覆制貼上的程式碼。
浮點數運算很難。
複製程式碼時一定要註明來源。別人可以據此提醒你重要的事情。
原文連結:https://programming.guide/worlds-most-copied-so-snippet.html
聲明:本文由CSDN翻譯,轉載請註明來源。


「去了太空就別回來了!」貝索斯還沒「上天」,就遭美國 5 萬多人請願:不準重返地球
位元組跳動1/3員工不支援取消大小周!庫克稱iPhone將採用可回收材料生產;清華博士接親被要求現場寫程式碼|極客頭條
相關文章
作者 | Andreas Lundblad 譯者 | 彎月 責編 | 歐陽姝黎2010年的某一天,我忙中偷閒去Stack Overflow上賺聲望值。於是,我看到了下面這個問題:怎樣將位元組數輸出成人
2021-06-22 21:01:29

6月17日,微軟方面正式宣佈:公司現任CEO薩提亞·納德拉接替約翰·湯普森擔任董事長的提議得到董事會全票通過。一人擔任微軟的CEO與董事長,這是繼比爾蓋茨辭職後,微軟20年以來的
2021-06-22 20:59:47

魚羊 發自 凹非寺 量子位 報道 | 公眾號 QbitAICVer翹首以盼的CVPR 2021,它來了它來了。本屆CVPR論文錄用率,較去年略有回升,但競爭依然激烈——在7039篇有效投稿中,最終有1661
2021-06-22 20:59:15

儘管近年來我國在半導體技術方面進步不小,但在很多晶片細分領域仍然受制於人,例如MCU晶片。所謂MCU晶片,指的是微控制單元,可以將CPU頻率與規格進行適當縮減,同時還能起到將記憶
2021-06-22 20:58:17
【CSDN 編者按】總結:靈活解耦、業務分離、單一責任、已維護,那麼就可以使用觀察者模式了。 作者 | 龍臺 責編 | 歐陽姝黎 前言 《設計模式實戰》系列目前已經寫了 7 篇
2021-06-22 20:39:57

看了魅族618「這次一定」功能點評優大賽,你有沒有被種草?反正筆者我是入坑了,只怪魅族18系列太搶眼!魅族18系列是魅族今年年初推出的一款旗艦機,它的第一個亮點就是小屏。在眾多
2021-06-22 20:39:28