
作者 | FinGet 責編 | 歐陽姝黎JS程式碼的執行,主要分為兩個個階段:編譯階段、執行階段。本文所有內容基於V8引擎。前言 v8引擎v8引擎工作原理:V8由許多子模組構成,其中這
2021-06-25 03:25:18

JS程式碼的執行,主要分為兩個個階段:編譯階段、執行階段。本文所有內容基於V8引擎。

v8引擎工作原理:

V8由許多子模組構成,其中這4個模組是最重要的:
通常有兩種類型的直譯器,基於棧 (Stack-based)和基於寄存器 (Register-based),基於棧的直譯器使用棧來儲存函數參數、中間運算結果、變數等;基於寄存器的虛擬機器則支援寄存器的指令操作,使用寄存器來儲存參數、中間計算結果。通常,基於棧的虛擬機器也定義了少量的寄存器,基於寄存器的虛擬機器也有堆棧,其區別體現在它們提供的指令集體系。大多數直譯器都是基於棧的,比如 Java 虛擬機器,.Net 虛擬機器,還有早期的 V8 虛擬機器。基於堆棧的虛擬機器在處理函數呼叫、解決遞迴問題和切換上下文時簡單明快。而現在的 V8 虛擬機器則採用了基於寄存器的設計,它將一些中間資料儲存到寄存器中。基於寄存器的直譯器架構:
如果一個函數被多次呼叫,那麼就會被標記為熱點函數,那麼就會經過TurboFan轉換成優化的機器碼,提高程式碼的執行效能;
但是,機器碼實際上也會被還原為ByteCode,這是因為如果後續執行函數的過程中,類型發生了變化(比如sum函數原來執行的是number類型,後來執行變成了string類型),之前優化的機器碼並不能正確的處理運算,就會逆向的轉換成位元組碼;
棧的特點是"LIFO,即後進先出(Last in, first out)"。資料儲存時只能從頂部逐個存入,取出時也需從頂部逐個取出。

堆的特點是"無序"的key-value"鍵值對"儲存方式。堆的存取方式跟順序沒有關係,不侷限出入口。

佇列的特點是是"FIFO,即先進先出(First in, first out)" 。資料存取時"從隊尾插入,從隊頭取出"。
"與棧的區別:棧的存入取出都在頂部一個出入口,而佇列分兩個,一個出口,一個入口"。


將由字元組成的字元串分解成(對程式語言來說)有意義的程式碼塊,這些程式碼塊被稱為詞法單元(token)。

[
{
"type": "Keyword",
"value": "var"
},
{
"type": "Identifier",
"value": "name"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "String",
"value": "'finget'"
},
{
"type": "Punctuator",
"value": ";"
}
]
這個過程是將詞法單元流(陣列)轉換成一個由元素逐級巢狀所組成的代表了程式語法結構的樹。這個樹被稱為「抽象語法樹」(Abstract Syntax Tree,AST)。
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "name"
},
"init": {
"type": "Literal",
"value": "finget",
"raw": "'finget'"
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}
在此過程中,如果原始碼不符合語法規則,則會終止,並拋出「語法錯誤」。

這裡有個工具,可以實時生成語法樹,可以試試esprima。
可以用node node --print-bytecode檢視位元組碼:
// test.js
function getMyname() {
var myname = 'finget';
console.log(myname);
}
getMyname();
node --print-bytecode test.js
...
[generated bytecode for function: getMyname (0x10ca700104e9 <SharedFunctionInfo getMyname>)]
Parameter count 1
Register count 3
Frame size 24
18 E> 0x10ca70010e86 @ 0 : a7 StackCheck
37 S> 0x10ca70010e87 @ 1 : 12 00 LdaConstant [0]
0x10ca70010e89 @ 3 : 26 fb Star r0
48 S> 0x10ca70010e8b @ 5 : 13 01 00 LdaGlobal [1], [0]
0x10ca70010e8e @ 8 : 26 f9 Star r2
56 E> 0x10ca70010e90 @ 10 : 28 f9 02 02 LdaNamedProperty r2, [2], [2]
0x10ca70010e94 @ 14 : 26 fa Star r1
56 E> 0x10ca70010e96 @ 16 : 59 fa f9 fb 04 CallProperty1 r1, r2, r0, [4]
0x10ca70010e9b @ 21 : 0d LdaUndefined
69 S> 0x10ca70010e9c @ 22 : ab Return
Constant pool (size = 3)
Handler Table (size = 0)
...
這裡涉及到一個很重要的概念:JIT(Just-in-time)一邊解釋,一邊執行。
它是如何工作的呢(結合第一張流程圖來看):
1.在 JavaScript 引擎中增加一個監視器(也叫分析器)。監視器監控著程式碼的運行情況,記錄程式碼一共運行了多少次、如何運行的等資訊,如果同一行程式碼運行了幾次,這個程式碼段就被標記成了 「warm」,如果運行了很多次,則被標記成 「hot」;
2.(基線編譯器)如果一段程式碼變成了 「warm」,那麼 JIT 就把它送到基線編譯器去編譯,並且把編譯結果儲存起來。比如,監視器監視到了,某行、某個變數執行同樣的程式碼、使用了同樣的變數類型,那麼就會把編譯後的版本,替換這一行程式碼的執行,並且儲存;
3.(優化編譯器)如果一個程式碼段變得 「hot」,監視器會把它傳送到優化編譯器中。生成一個更快速和高效的程式碼版本出來,並且儲存。例如:迴圈加一個物件屬性時,假設它是 INT 類型,優先做 INT 類型的判斷;
4.(反優化 Deoptimization)可是對於 JavaScript 從來就沒有確定這麼一說,前 99 個物件屬性保持著 INT 類型,可能第 100 個就沒有這個屬性了,那麼這時候 JIT 會認為做了一個錯誤的假設,並且把優化程式碼丟掉,執行過程將會回到直譯器或者基線編譯器,這一過程叫做反優化。
作用域是一套規則,用來管理引擎如何查詢變數。在es5之前,js只有全局作用域及函數作用域。es6引入了塊級作用域。但是這個塊級別作用域需要注意的是不是{}的作用域,而是let,const關鍵字的塊級作用域。
var name = 'FinGet';
function fn() {
var age = 18;
console.log(name);
}
在解析時就會確定作用域:

簡單的來說,作用域就是個盒子,規定了變數和函數的可訪問範圍以及他們的生命週期。
詞法作用域就是指作用域是由程式碼中函數聲明的位置來決定的,所以詞法作用域是靜態的作用域,通過它就能夠預測程式碼在執行過程中如何查詢標識符。
function fn() {
console.log(myName)
}
function fn1() {
var myName = " FinGet "
fn()
}
var myName = " global_finget "
fn1()
上面程式碼列印的結果是:global_finget,這就是因為在編譯階段就已經確定了作用域,fn是定義在全局作用域中的,它在自己內部找不到myName就會去全局作用域中找,不會在fn1中查詢。
遇到函數執行的時候,就會創建一個執行上下文。執行上下文是當前 JavaScript 程式碼被解析和執行時所在環境的抽象概念。
JavaScript 中有三種執行上下文類型:
執行上下文的創建分為兩個階段創建:1.創建階段 2.執行階段
在任意的 JavaScript 程式碼被執行時,執行上下文處於創建階段。在創建階段中總共發生了三件事情:
ExecutionContext = {
ThisBinding = <this value>, // 確定this
LexicalEnvironment = { ... }, // 詞法環境
VariableEnvironment = { ... }, // 變數環境
}
在全局執行上下文中,this 的值指向全局物件,在瀏覽器中,this 的值指向 window 物件。在函數執行上下文中,this 的值取決於函數的呼叫方式。如果它被一個物件引用呼叫,那麼 this 的值被設定為該物件,否則 this 的值被設定為全局物件或 undefined(嚴格模式下)。
詞法環境是一個包含標識符變數對映的結構。(這裡的標識符表示變數/函數的名稱,變數是對實際物件【包括函數類型物件】或原始值的引用)。在詞法環境中,有兩個組成部分:(1)環境記錄(environment record)(2)對外部環境的引用
詞法環境有兩種類型:
全局環境(在全局執行上下文中)是一個沒有外部環境的詞法環境。全局環境的外部環境引用為 null。它擁有一個全局物件(window 物件)及其關聯的方法和屬性(例如陣列方法)以及任何使用者自定義的全局變數,this 的值指向這個全局物件。
函數環境,使用者在函數中定義的變數被儲存在環境記錄中。對外部環境的引用可以是全局環境,也可以是包含內部函數的外部函數環境。
注意:對於函數環境而言,環境記錄 還包含了一個 arguments 物件,該物件包含了索引和傳遞給函數的參數之間的對映以及傳遞給函數的參數的長度(數量)。
它也是一個詞法環境,其 EnvironmentRecord 包含了由 VariableStatements 在此執行上下文創建的繫結。
如上所述,變數環境也是一個詞法環境,因此它具有上面定義的詞法環境的所有屬性。
示例程式碼:
let a = 20;
const b = 30;
var c;
function multiply(e, f) {
var g = 20;
return e * f * g;
}
c = multiply(20, 30);
執行上下文:
GlobalExectionContext = {
ThisBinding: <Global Object>,
LexicalEnvironment: {
EnvironmentRecord: {
Type: "Object",
// 標識符繫結在這裡
a: < uninitialized >,
b: < uninitialized >,
multiply: < func >
}
outer: <null>
},
VariableEnvironment: {
EnvironmentRecord: {
Type: "Object",
// 標識符繫結在這裡
c: undefined,
}
outer: <null>
}
}
FunctionExectionContext = {
ThisBinding: <Global Object>,
LexicalEnvironment: {
EnvironmentRecord: {
Type: "Declarative",
// 標識符繫結在這裡
Arguments: {0: 20, 1: 30, length: 2},
},
outer: <GlobalLexicalEnvironment> // 指定全局環境
},
VariableEnvironment: {
EnvironmentRecord: {
Type: "Declarative",
// 標識符繫結在這裡
g: undefined
},
outer: <GlobalLexicalEnvironment>
}
}
仔細看上面的:a: < uninitialized >,c: undefined。所以你在let a定義前console.log(a)的時候會得到Uncaught ReferenceError: Cannot access 'a' before initialization。
變數環境元件(VariableEnvironment) 是用來登記var function變數聲明,詞法環境元件(LexicalEnvironment)是用來登記let const class等變數聲明。
在ES6之前都沒有塊級作用域,ES6之後我們可以用let const來聲明塊級作用域,有這兩個詞法環境是為了實現塊級作用域的同時不影響var變數聲明和函數聲明,具體如下:
function foo(){
var a = 1
let b = 2
{
let b = 3
var c = 4
let d = 5
console.log(a)
console.log(b)
}
console.log(b)
console.log(c)
console.log(d)
}
foo()

從圖中可以看出,當進入函數的作用域塊時,作用域塊中通過let聲明的變數,會被存放在詞法環境的一個單獨的區域中,這個區域中的變數並不影響作用域塊外面的變數,比如在作用域外面聲明瞭變數b,在該作用域塊內部也聲明瞭變數b,當執行到作用域內部時,它們都是獨立的存在。
其實,在詞法環境內部,維護了一個小型棧結構,棧底是函數最外層的變數,進入一個作用域塊後,就會把該作用域塊內部的變數壓到棧頂;當作用域執行完成之後,該作用域的資訊就會從棧頂彈出,這就是詞法環境的結構。需要注意下,我這裡所講的變數是指通過let或者const聲明的變數。
再接下來,當執行到作用域塊中的console.log(a)這行程式碼時,就需要在詞法環境和變數環境中查詢變數a的值了,具體查詢方式是:沿著詞法環境的棧頂向下查詢,如果在詞法環境中的某個塊中查詢到了,就直接返回給JavaScript引擎,如果沒有查詢到,那麼繼續在變數環境中查詢。
每個函數都會有自己的執行上下文,多個執行上下文就會以棧(呼叫棧)的方式來管理。
function a () {
console.log('In fn a')
function b () {
console.log('In fn b')
function c () {
console.log('In fn c')
}
c()
}
b()
}
a()


可以用這個工具試一下,更直觀的觀察進棧和出棧javascript visualizer 工具。
看這個圖就可以看出作用域鏈了吧,很直觀。作用域鏈就是在執行上下文創建階段確定的。有了執行的環境,才能確定它應該和誰構成作用域鏈。

棧是臨時儲存空間,主要儲存局部變數和函數呼叫,內小且儲存連續,操作起來簡單方便,一般由系統自動分配,自動回收,所以文章內所說的垃圾回收,都是基於堆記憶體。
基本類型資料(Number, Boolean, String, Null, Undefined, Symbol, BigInt)儲存在在棧記憶體中。引用類型資料儲存在堆記憶體中,引用資料類型的變數是一個指向堆記憶體中實際物件的引用,存在棧中。
為什麼基本資料類型存儲在棧中,引用資料類型儲存在堆中?
JavaScript引擎需要用棧來維護程式執行期間的上下文的狀態,如果棧空間大了的話,所有資料都存放在棧空間裡面,會影響到上下文切換的效率,進而影響整個程式的執行效率。

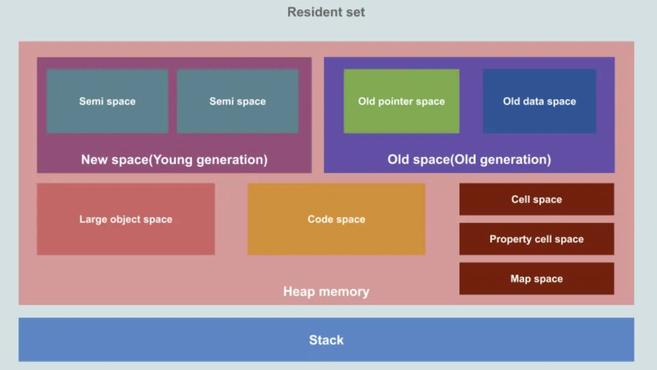
這裡用來儲存物件和動態資料,這是記憶體中最大的區域,並且是GC(Garbage collection 垃圾回收)工作的地方。不過,並不是所有的堆記憶體都可以進行GC,只有新生代和老生代被GC管理。堆可以進一步細分為下面這樣:
Old pointer space:存活下來的包含指向其他物件指針的物件
Old data space:存活下來的只包含資料的物件。
代際假說有以下兩個特點:
在 V8 中會把堆分為新生代和老生代兩個區域,新生代中存放的是生存時間短的物件,老生代中存放的生存時間久的物件。
新生區通常只支援 1~8M 的容量,而老生區支援的容量就大很多了。對於這兩塊區域,V8 分別使用兩個不同的垃圾回收器,以便更高效地實施垃圾回收。
新生代中用Scavenge演算法來處理。所謂 Scavenge 演算法,是把新生代空間對半劃分為兩個區域,一半是物件區域,一半是空閒區域。

新加入的物件都會存放到物件區域,當物件區域快被寫滿時,就需要執行一次垃圾清理操作。


由於新生代中採用的 Scavenge 演算法,所以每次執行清理操作時,都需要將存活的物件從物件區域複製到空閒區域。但複製操作需要時間成本,如果新生區空間設定得太大了,那麼每次清理的時間就會過久,所以為了執行效率,一般新生區的空間會被設定得比較小。
也正是因為新生區的空間不大,所以很容易被存活的物件裝滿整個區域。為了解決這個問題,JavaScript 引擎採用了物件晉升策略,也就是經過兩次垃圾回收依然還存活的物件,會被移動到老生區中。
Mark-Sweep處理時分為兩階段,標記階段和清理階段,看起來與Scavenge類似,不同的是,Scavenge演算法是複製活動物件,而由於在老生代中活動物件佔大多數,所以Mark-Sweep在標記了活動物件和非活動物件之後,直接把非活動物件清除。

由於Mark-Sweep完成之後,老生代的記憶體中產生了很多記憶體碎片,若不清理這些記憶體碎片,如果出現需要分配一個大物件的時候,這時所有的碎片空間都完全無法完成分配,就會提前觸發垃圾回收,而這次回收其實不是必要的。
為了解決記憶體碎片問題,Mark-Compact被提出,它是在是在 Mark-Sweep的基礎上演進而來的,相比Mark-Sweep,Mark-Compact添加了活動物件整理階段,將所有的活動物件往一端移動,移動完成後,直接清理掉邊界外的記憶體。

垃圾回收如果耗費時間,那麼主執行緒的JS操作就要停下來等待垃圾回收完成繼續執行,我們把這種行為叫做全停頓(Stop-The-World)。

為了降低老生代的垃圾回收而造成的卡頓,V8 將標記過程分為一個個的子標記過程,同時讓垃圾回收標記和 JavaScript 應用邏輯交替進行,直到標記階段完成,我們把這個演算法稱為增量標記(Incremental Marking)演算法。如下圖所示:

增量標記只是對活動物件和非活動物件進行標記,惰性清理用來真正的清理釋放記憶體。當增量標記完成後,假如當前的可用記憶體足以讓我們快速的執行程式碼,其實我們是沒必要立即清理記憶體的,可以將清理的過程延遲一下,讓JavaScript邏輯程式碼先執行,也無需一次性清理完所有非活動物件記憶體,垃圾回收器會按需逐一進行清理,直到所有的頁都清理完畢。
併發式GC允許在在垃圾回收的同時不需要將主執行緒掛起,兩者可以同時進行,只有在個別時候需要短暫停下來讓垃圾回收器做一些特殊的操作。但是這種方式也要面對增量回收的問題,就是在垃圾回收過程中,由於JavaScript程式碼在執行,堆中的物件的引用關係隨時可能會變化,所以也要進行寫屏障操作。

並行式GC允許主執行緒和輔助執行緒同時執行同樣的GC工作,這樣可以讓輔助執行緒來分擔主執行緒的GC工作,使得垃圾回收所耗費的時間等於總時間除以參與的執行緒數量(加上一些同步開銷)。


在這裡對前輩大佬表示敬意,查找了很多資料,如有遺漏,還請見諒。文中如果有誤,還望及時指出,感謝!



相關文章
作者 | FinGet 責編 | 歐陽姝黎JS程式碼的執行,主要分為兩個個階段:編譯階段、執行階段。本文所有內容基於V8引擎。前言 v8引擎v8引擎工作原理:V8由許多子模組構成,其中這
2021-06-25 03:25:18

大資料文摘授權轉載自AI科技評論作者:陳大鑫、陳彩嫻昨晚脈脈上有網友爆料,位元組跳動一位實習生刪除了公司所有輕量級別的機器學習模型!什麼是lite模型?該樓主表示,lite模型就是
2021-06-25 03:23:03
作者 | 郭人通提到搜尋引擎,大家首先想到的一般是ElasticSearch。在文字作為資訊主要載體的階段,ElasticSearch技術棧是文字搜尋的最佳實踐。然而目前搜尋領域的資料基礎發生
2021-06-25 03:03:59

據悉以加盟製為主的快遞企業正瘋狂壓榨快遞小哥和加盟商,導致如此結果應該是快遞行業競爭日漸激烈所致,這些加盟制的快遞企業已感受到這個行業的衰落而選擇最後的瘋狂。快遞企
2021-06-25 03:03:43

儘管在Windows 11正式推出之前,網上已經洩露了Win11的ISO,同時有相當多的使用者開始嘗試Win11,但這並不妨礙微軟在今天深夜舉辦釋出會,向大家正式推出Win11,在今天的釋出會上,微軟
2021-06-25 03:03:19

【微創WEC科技】近期,關於iPhone 13爆料逐漸增多,近期的爆料稱iPhone 13可能不叫iPhone 13,而是叫iPhone 12s,其實叫啥都沒關係,只是一個名稱罷了。但新iPhone將採用小「劉海」設
2021-06-25 03:02:59