來源:資料STUDIO作者:雲朵君最近房地產市場進一步收緊,多地地方政府出臺各種收緊政策,以保證房地產健康發展,因此雲朵君就想到運用Python網路爬蟲,抓取部分房產資訊,瞭解下最近房地
2021-07-17 03:04:32
來源:資料STUDIO
作者:雲朵君
最近房地產市場進一步收緊,多地地方政府出臺各種收緊政策,以保證房地產健康發展,因此雲朵君就想到運用Python網路爬蟲,抓取部分房產資訊,瞭解下最近房地產的情況。

接下來以房天下二手房資訊,以獲取某個城市各個區域二手房房產資訊及價格,來一起學習下Python網路爬蟲的基本方法。
備註,本文僅以學習交流,對於爬蟲淺嘗輒止,以免對伺服器增加負擔。
運用谷歌瀏覽器開發者工具分析網站
# 各區域網站地址如下規律
https://cd.esf.fang.com/house-a0129/
https://cd.esf.fang.com/house-a0130/
https://cd.esf.fang.com/house-a0132/
# 每個區域不同頁的網址規律
https://cd.esf.fang.com/house-a0132/i32/
https://cd.esf.fang.com/house-a0132/i33/
https://cd.esf.fang.com/house-a0132/i34/
# 因此可定義網址形式如下
base_url = 'https://cd.esf.fang.com{}'.format(region_href)
tail_url = 'i3{}/'.format(page)
url = base_url + tail_url
接下來重點獲取region_href, page可以迴圈獲取。
在HTML中找到所有區域及region_href。
from requests_html import UserAgent
import requests
from bs4 import BeautifulSoup
user_agent = UserAgent().random
url = 'https://cd.esf.fang.com/'
res = requests.get(url, headers={"User-Agent": user_agent})
soup = BeautifulSoup(res.text, features='lxml') # 對html進行解析,完成初始化
results = soup.find_all(attrs={'class': "clearfix choose_screen floatl"})
regions = results[0].find_all(name='a')
region_href_list = []
region_name_list = []
for region in regions:
region_href_list.append(region['href'])
region_name_list.append(region.text)
本次使用
BeautifulSoup解析網頁資料,獲取region_href及對應行政區域名稱region_name。
由於每個行政區域及其各頁資料可重複迴圈獲取,因此這裡只介紹一個區域(青羊區)的第一頁。
分析每條資料所存在的地方。
檢視每個資訊所在的節點。
import re
regex = re.compile('s(S+)s')
results = soup.find_all(attrs={'class': 'clearfix', 'dataflag': "bg"})
result = results
content = result.dd
# 獲取項目簡述
title = regex.findall(content.h4.a.text)
','.join(title)
>>> '精裝修套三,視野好'
# 獲取項目名稱與地址
name = regex.findall(content.find_all(name='p', attrs={'class': 'add_shop'})[0].text)[0]
address = regex.findall(content.find_all(name='p', attrs={'class': 'add_shop'})[0].text)[1]
name
>>> '成都花園上城'
address
>>> '貝森-成都花園上城家園南街1號'
# 獲取項目描述,包括戶型、區域、樓層、朝向、建築年代
describe = regex.findall(content.find_all(name='p', attrs={'class': 'tel_shop'})[0].text)
describe
>>> ['3室2廳', '|', '141.26㎡', '|', '中層(共22層)', '|', '西向', '|', '2008年建', '|', '楊斌']
# 獲取優勢標籤
labels = regex.findall(content.find_all(name='p', attrs={'class': 'clearfix label'})[0].text)
labels
>>> ['距7號線東坡路站約830米']
# 獲取價格
prices = result.find_all(name='dd', attrs={'class': 'price_right'})[0].text
prices
>>> 'nn380萬n26900元/㎡n'
其餘部分只需要迴圈獲取即可。
import pandas as pd
data = pd.read_csv("成都二手房_青羊.csv")
data.sample(5)
本次獲取一個行政區共6027個二手房資訊。
data.shape
>>> (6027, 13)
由於此網站監控較為嚴格,可利用selenium模擬瀏覽器一定程度上規避反爬機制。
分析網頁的方法同上,但此次並不是迴圈請求網頁獲取網頁資料,而是通過模擬瀏覽器操作,再通過Xpath獲取資料。
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
from requests_html import UserAgent
from openpyxl import Workbook
import os
import json
import numpy as np
def init():
"""
初始化谷歌瀏覽器驅動
:return:
"""
chrome_options = webdriver.ChromeOptions()
# 不載入圖片
prefs = {"profile.managed_default_content_setting.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 使用headless無介面瀏覽模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 載入谷歌瀏覽器驅動
browser = webdriver.Chrome(options=chrome_options,
executable_path='chromedriver.exe')
browser.get('https://cd.esf.fang.com/')
wait = WebDriverWait(browser, 10) # 最多等待十秒
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'screen_al')))
return browser
此方法是根據xpath路徑獲取資料。
content_list = browser.find_elements_by_xpath("//div[@class='shop_list shop_list_4']/dl")
content_list
得到以 WebElement物件為元素的列表。
可通過遍歷的方法遍歷獲取。
content = content_list[0]
describe = content.find_elements_by_xpath('dd')[0].text
price = content.find_elements_by_xpath('dd')[1].text
row = [describe, price, city]
row
其中一天資訊如下。
def get_page_content(browser, sheet, region):
"""
按頁獲取每頁內容
:param browser: 瀏覽器驅動
:param sheet: excel 工作表
:param region: 行政區域名稱
:return:
"""
content_list = browser.find_elements_by_xpath("//div[@class='shop_list shop_list_4']/dl")
for content in content_list:
try:
describe = content.find_elements_by_xpath('dd')[0].text
price = content.find_elements_by_xpath('dd')[1].text
row = [describe, price, region]
sheet.append(row)
except:
pass
return browser, sheet
def get_region_content(browser, href, sheet, region):
"""
獲取行政區域內容
:param browser:谷歌瀏覽器驅動
:param href: 請求地址
:param sheet: excel 工作表
:param region: 行政區域
:return:
"""
print(f'正在爬取{region}區'.center(50, '*'))
browser.find_element_by_xpath(f"//a[@href='{href}']").click()
# 滑動到瀏覽器底部,已保證全部載入完成
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(2)
# 重新滑動到瀏覽器頂部
browser.execute_script('window.scrollTo(0,0)')
wait = WebDriverWait(browser, 15) # 最多等待十秒
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'page_box')))
browser, sheet = get_page_content(browser, sheet, region)
time.sleep(np.random.randint(10, 15))
# 按頁獲取每一頁的內容
for page in range(2, 101):
print(f'正在爬取{region}區的第{page}頁'.center(30, '-'))
try:
browser.find_element_by_xpath(f"//a[@href='{href}i3{page}/']").click()
browser, sheet = get_page_content(browser, sheet, region)
time.sleep(np.random.randint(14, 15))
except:
break
return browser, sheet
def get_content():
region_href_list, region_name_list = get_href_list()
for ind, href in enumerate(region_href_list):
browser = init()
region = region_name_list[ind]
wb = Workbook()
sheet = wb.active
sheet.title = region
header = ['描述', '價格', '行政區']
sheet.append(header)
browser, sheet = get_region_content(browser, href, sheet, region)
wb.save(f'{region}.xlsx')
print(f'{region}.xlsx已經儲存完畢'.center(60, '#'))
time.sleep(np.random.randint(15, 20))
browser.quit()
獲取資料後,可以對資料清洗並分析。
相關文章

來源:資料STUDIO作者:雲朵君最近房地產市場進一步收緊,多地地方政府出臺各種收緊政策,以保證房地產健康發展,因此雲朵君就想到運用Python網路爬蟲,抓取部分房產資訊,瞭解下最近房地
2021-07-17 03:04:32

機器之心報道機器之心編輯部伴隨著 11 支獲獎隊伍的頒獎典禮舉行,2021 WAIC 黑客鬆圓滿落下帷幕。2021 世界人工智慧大會(WAIC)黑客鬆近日於上海舉辦。WAIC 黑客馬拉松作為 WAI
2021-07-17 03:04:27

明敏 發自 凹非寺量子位 報道 | 公眾號 QbitAIAI生成的文字好不好,最權威的評估者竟然不是人類自己?最近,華盛頓大學和艾倫人工智慧研究院的學者們在研究中發現:未經過訓練的人
2021-07-17 03:04:18
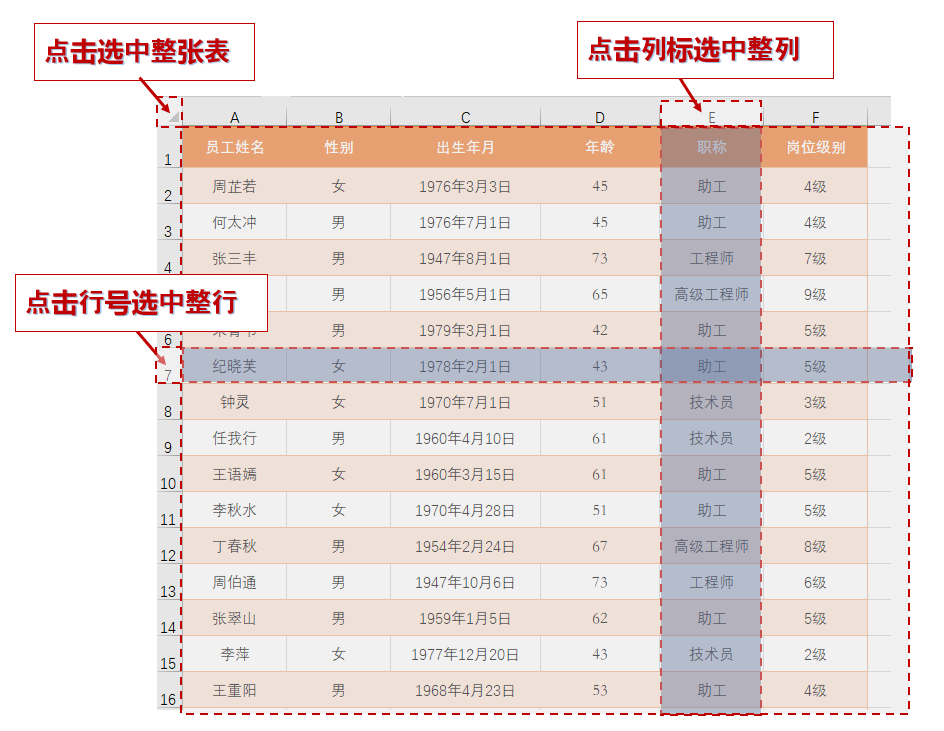
上次的比試,彪彪(滑鼠代稱)心有不甘,總想找機會,再與鍵鍵(鍵盤代稱)比試一場。他為此在Excel武場苦練了一番,終於覺得略有小成,便急匆匆地去找鍵鍵,約武。彪彪見到鍵鍵說:今日有什麼事
2021-07-17 03:04:08

7 月 15 日晚,央視 CCTV 2 財經頻道《經濟半小時》欄目帶來了一期以「開源軟體」為主題的專題報道。報道指出,開源軟體在當今社會的重要性和影響力不言而喻,人們日常生活中使用
2021-07-17 03:03:53
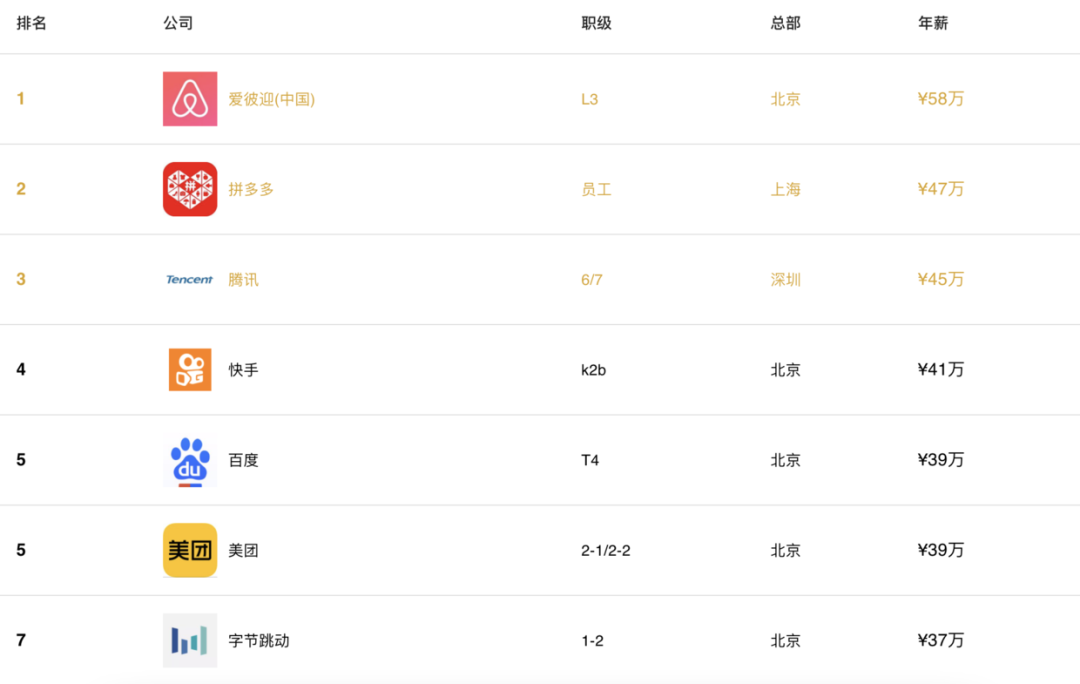
本文中出現數據均以《2021年網際網路產業求職指南》為準。 一、設計和產品競爭最激烈2020年的從求職競爭的角度來看,UI設計崗位以及產品經理崗位是競爭最激烈的。資料顯示一
2021-07-17 03:03:46