嗨嘍,各位同學又到了公佈CDA資料分析師認證考試Level Ⅲ的模擬試題時間了,今天給大家帶來的是模擬試題(一)中的31-35題。(單選題)不過,在出題前,要公佈上一期Level Ⅲ 中26-30題的
2021-08-04 03:03:59
嗨嘍,各位同學又到了公佈CDA資料分析師認證考試Level Ⅲ的模擬試題時間了,今天給大家帶來的是模擬試題(一)中的31-35題。(單選題)
不過,在出題前,要公佈上一期Level Ⅲ 中26-30題的答案,大家一起來看!
26、B
27、A
28、C
29、A
30、B
31、自然語言處理工作中,在自動建構關鍵詞(非控制字彙)時,經常採用的方法是?
A.Controlled Vocabulay(控制字彙)
B.Inversion of Terms(逐項翻轉)
C.Inverse Document Frequency(IDF)
D.Full-Text Scanning
32、向量空間模型是資訊檢索技術,下面有關向量空間模型(VSM)的描述中,錯誤的是:
A.以向量來表示文件後,兩者的夾角越小說明相似度越高。
B.文字特徵詞的向量權重可通過TF-IDF實現,從而保留文字詞序結構資訊
C.在向量空間模型中,當有新文件加入時,需要重新計算特徵詞的權重
D.基於向量的文字相似度計算中,除了內積、Dice係數、夾角餘弦,還可用Jaccard方法
33.全文掃描、逐項反轉、簽名檔案是資訊檢索技術中的基本檢索法。資訊檢索技術中的簽名檔案(Signature File)指的是?
A.計算點與點之間的距離來找出和此查詢相近似的檔案並加以排序輸出
B.利用餘弦相似度求出檔案的相似程度,並將檔案依相似程度由大到小排序輸出
C.將待查的字元串直接和原文字元串進行快速字元串比對
D.簽名檔利用重迭編碼的技巧, 將檔案轉換成一固定長度的簽名以加速字元串比對。
34.漢語自動分詞是中文資訊處理的重要基石.困擾漢語自動分詞發展的原因有很多,對歧義欄位的排除是亟待解決的幾個難題之一。以下哪一項不屬於針對多義詞的歧義排除經典演算法?
A.基於規則的演算法
B.基於概率統計模型的演算法
C.規則和統計相結合的演算法
D.基於協同過濾演算法
35.Word2vec,是一群用來產生詞向量的相關模型。這些模型為淺而雙層的神經網路,用來訓練以重新建構語言學之詞文字。關於word2vec模型,下面說法不正確的是:
A.得到的詞向量維度小,可以節省儲存和計算資源
B.考慮了全局語料庫的資訊
C.無法解決多義詞的問題
D.可以表示詞和詞之間的關係
認真答題哦,我們將在下一期公佈正確答案,敬請期待。

登入CDA認證考試官網註冊報名
Level Ⅰ:1200 RMB
Level Ⅱ:1700 RMB
Level Ⅲ:2000 RMB
Level Ⅰ:隨報隨考。
Level Ⅱ:隨報隨考。
Level Ⅲ:一年四屆(3、6、9、12月的最後一個週六),每屆考前一個月截止該屆報名。
Level Ⅰ+Ⅱ:中國內地30+省市,70+城市,250+考場。考生可選擇就近考場預約考試。
Level Ⅲ:中國內地30所城市,北京/上海/天津/重慶/成都/深圳/廣州/濟南/南京/杭州/蘇州/福州/太原/武漢/長沙/西安/貴陽/鄭州/南寧/昆明/烏魯木齊/瀋陽/哈爾濱/合肥/石家莊/呼和浩特/南昌/長春/大連/蘭州。
相關文章

嗨嘍,各位同學又到了公佈CDA資料分析師認證考試Level Ⅲ的模擬試題時間了,今天給大家帶來的是模擬試題(一)中的31-35題。(單選題)不過,在出題前,要公佈上一期Level Ⅲ 中26-30題的
2021-08-04 03:03:59

谷歌下一代 Pixel 手機不再會是高價低配的模樣了,而且還將用上自己特製的晶片,加強 AI 能力。 8 月 2 日,谷歌宣佈了自家下一代旗艦手機 Pixel 6 和 6Pro 的釋出計劃。在系統、
2021-08-04 03:03:52

見過了機械手捏易拉罐、盤「核桃」、玩魔方……見過它玩超級馬里奧嗎?下面就有一隻只有3根手指頭的機械手,「氣定神閒」地操縱著遊戲手柄順利通過馬里奧第一關。圖片ps.是不是
2021-08-04 03:03:32
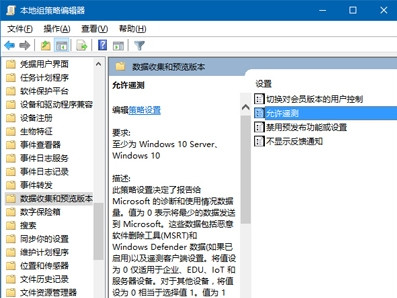
Win10系統具有特殊的遙測功能,主要是保護使用者的隱私,也可以為使用者設定安全級別設定,您如何為Win10計算機設定安全級別?讓我們來看看以下內容,有興趣的使用者可以看看。首先,Wi
2021-08-04 03:03:23
出品|開源中國文|局長維基媒體基金會 (Wikimedia Foundation) 宣佈正式採用 Vue.js 作為未來的 JavaScript 框架 —— 用於維基百科的底層引擎 MediaWiki。據介紹,維基媒體基
2021-08-04 03:03:17

參加面試不要遲到是最基本的,面試遲到第一印象很壞。另外就是注意基本的禮貌問題,很多時候我作為面試官面試的時候,進到會議室,求職者連個招呼也不打。這些內容就是提醒大家一下
2021-08-04 03:03:06